
Ethics on the edge: How New Zealand directors can lead with integrity
Leading with conscience, not just compliance – governance must evolve to keep pace with today’s ethical risks.

OPINION: As a director, you’ll be rightly focused on the benefits and risks of AI to your company (and you’re probably having some fun with Chat GPT).
But have you noticed the rise of synthetic data? Gartner predicts it will be the dominant form of data used for AI as early as 2024 (Andrew White, 24 July 2021).
A “synthetic” data set is one that’s artificially generated from a real-world data set in a way that preserves the statistical relationships within the real data.
Think of a real-world data set for 100 athletes, recording a variety of different physical and medical details for each person. Analysis of the real data will reveal all kinds of correlations between different variables – like height and daily protein consumption, weight and daily minutes of aerobic exercise, and dozens more.
You can then create a synthetic data set of, say, 500 athletes that preserves those same statistical correlations (or just some of them, depending on the level of fidelity you want), but with none of the individual datapoints being real – the height of individual 37 for example.
All those individual datapoints are randomly generated, but within certain boundaries so that, in the whole synthetic data set, the correlations you’re interested in stay the same as in the real data.
Data can be difficult, time-consuming, and costly to gather and analyse. Synthetic data will democratise these tasks by making data abundant.
It can be used to train machine learning models, as well as test software applications in a controlled environment. Synthetic data underpins the technology that generates undetectable fake faces and voices and many other emerging technologies and applications.
Synthetic data can also be relevant for developing social policy – health policy for example – as analysts can learn real things about the real world but without risks to the security or integrity of real data or to the privacy of real individuals.
The tech research and consulting firm Gartner predicts that over the next decade synthetic data will start to massively overshadow real data in AI models (Cem Dilmegani, 20 January 2023, AI Multiple).
Gartner projects that “By 2024, 60% of the data used for the development of AI and analytics projects will be synthetically generated” (Andrew White, 24 July 2021).
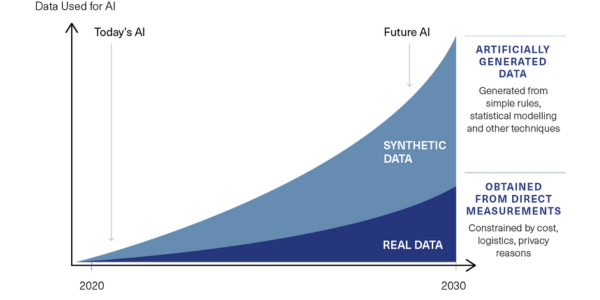
According to AI commentator Rob Toews, “the rise of synthetic data will completely transform the economics, ownership, strategic dynamics, even (geo)politics of data” (Forbes, 12 June 2022). He cites Ofir Zuk, CEO/founder of synthetic data startup Datagen, claiming that the total addressable market of synthetic data and the total addressable market of data will converge.
Data privacy is non-negotiable, especially personal data, and leaks pose an existential risk to companies. On the other hand, data is ever more central to many business models. Synthetic data lets companies model various offerings and customer behaviours without risk to their customers’ privacy. UK banks are already doing this at scale.
Testing and validation of software and machine-learning models can be done at vastly larger scale without security and privacy risks. The enormous investment in self-driving vehicles has been underpinned by gargantuan synthetic datasets, because using real-world video from vehicles driving the streets as input to the machine learning models would take at least 300 years of driving.
Better results and less bias can be achieved because, counter-intuitively, synthetic datasets can sometime be more accurate than real-world datasets. This is because the statistical properties contained within the synthetic data can more readily account for outlier incidents that can be missed by smaller real-world datasets (when a deer and a child run in front of your car simultaneously). Synthetic dataset can also be used to correct for bias.
Faster and cheaper collection, labelling, and analysis of data can democratise the use of what we used to call “big data”.
A privacy breach is not the only risk directors need to pay attention to as synthetic data comes to prominence. It can also be used for fraud and to maliciously deceive and manipulate.
If your company uses a lot of data, then synthetic data will probably become an option to improve performance in the next few years, if not now. That means you need to consider whether you have the appropriate checks and balances to ensure, for example, that your synthetic datasets aren’t biased, and that you’re guarding against malicious actors who might seek to create fake social media profiles for fake financial transactions.
A lot of work is being put into regulating the use of synthetic data and the ethical questions it raises (especially in the UK), but it is very early days. Directors have a responsibility to pay close attention to this matter, not only from a legal perspective but also to be “good citizens” when the law is not yet clear.
Synthetic data is here and overlaps with AI. It’s a major innovation in itself and we need to pay it just as much attention.
I wrote more extensively about synthetic data in the May 2023 issue of Policy Quarterly Synthetic Data and Public Policy: supporting real-world policymakers with algorithmically generated data | Policy Quarterly (victoria.ac.nz) , published by Te Herenga Waka Victoria University of Wellington.

Kevin Jenkins CMInstD is a professional director, founder of Martin Jenkins, and writes about the intersection of business, innovation and regulation.
The views expressed in this article do not reflect the position of the IoD unless explicitly stated.
Contribute your perspectives and expertise on an area of governance to the IoD membership and governance community. Contact us mail@iod.org.nz


